
What is data compression?
Data compression is a set of steps for packing data into a smaller space by reducing the number of bits needed to represent data while allowing for the original data to be seen again.
Compressing data can save storage capacity, speed up file transfer, and decrease costs for storage hardware and network bandwidth.
The design of data compression schemes involves trade-offs among various factors, for example, the degree of compression, the amount of distortion introduced, the computational resources required for compression and decompression etc.
How compression works
Compression is performed by a program that uses a formula or algorithm to determine how to shrink the size of the data.
Data compression may be lossy or lossless.
- Lossless Compression:
Lossless compression enables the restoration of a file to its original state, without the loss of a single bit of data, when the file is decompressed.
It is done by eliminating data redundancy. Data redundancy is a condition created within a database or data storage environment in which the same piece of data is held in multiple places.
By eliminating redundancy, you are left with just one instance of each bit of data.
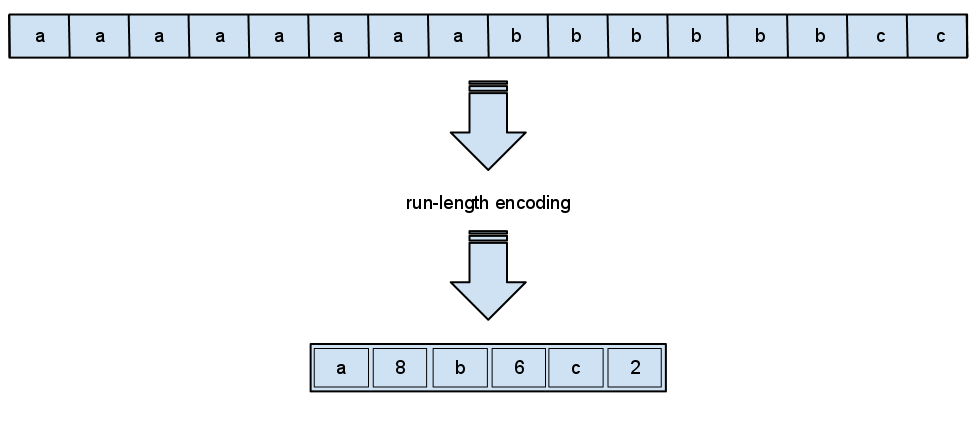
For example, data containing “AAAAABBBB” can be compressed into “5A4B”. This type of compression is called “run-length encoding” because the “run” of a character is defined. In the above example, there are two runs: one of 5 A’s, another of 4 B’s.
However, run-length encoding only works on long pieces of the same value of data. If your data contains “ABBAABAAB”, run-length encoding would yield “1A2B2A1B2A1B”; which is longer than the original. Here another method can be used: checking how often a particular value comes up in the whole data package, called frequency compression.
The most common kind of frequency compression is called Huffman coding. The basic idea is to give each distinct value in a piece of data a code: more frequent values get shorter codes, less frequent ones get longer codes.
Lossless compression is the typical approach with executables, and text and spreadsheet files, where the loss of data would change the information.
Examples of lossless compression:
Archiving formats: Zip, GZip, bZip2, 7-Zip, etc.
Images/diagrams: GIF, PNG, PCX
Video: HEVC, MPEG-4 AVC
- Lossy compression

Lossy compression permanently eliminates bits of data that are redundant, unimportant or imperceptible.
Lossy compression is used for graphics, audio, video, and images, where the removal of some data bits has little or no discernible effect on the representation of the content.
A downside to this method is a reduction in quality if you compress the same file over and over again using the lossy method.
Examples of lossy compression:
Images: JPEG
Audio: MP3, Windows Media
Video: MPEG, DivX, Windows Video
- Lossy vs Lossless
While the performance of lossless compression is measured by its degree of compression, lossy compression is evaluated on the basis of the error it introduces.
Several compression techniques are used today, for example, Burrows-Wheeler technique, Huffman encoding, Entropy encoding etc.
Most cannot stand on their own but must be combined together to form a compression algorithm. Examples of compression algorithms include LZW and its various improvisations, DEFLATE etc.